서포트 벡터 머신
서포트 벡터 머신(영: support vector machine, SVM)은, 교사 있어 학습을 이용하는 패턴 인식 모델의 하나이다.분류나 회귀에 적용할 수 있다.1963년에 Vladimir N. Vapnik, Alexey Ya. Chervonenkis가 선형 서포트 벡터 머신을 발표해[1], 1992년에 Bernhard E. Boser, Isabelle M. Guyon, Vladimir N. Vapnik가 비선형으로 확장했다.
서포트 벡터 머신은, 현재 알려져 있는 수법 중(안)에서도 인식 성능이 뛰어난 학습 모델의 하나이다.서포트 벡터 머신이 뛰어난 인식 성능을 발휘할 수 있는 이유는, 미학습 데이터에 대해서 높은 식별 성능을 얻기 위한 궁리가 있기 때문에 있다.
목차
기본적인 생각
서포트 벡터 머신은, 선형 입력 소자를 이용해 2 클래스의 패턴 식별기를 구성하는 수법이다.훈련 샘플로부터, 각 데이터점과의 거리가 최대가 되는 마진 최대화초평면을 요구한다고 하는 기준(초평면 분리 정리)으로 선형 입력 소자의 파라미터를 학습한다.
가장 간단한 경우인, 주어진 데이터를 선형 로 분리하는 것이 가능한(예를 들면, 3 차원의 데이터를 2 차원 평면에서 완전하게 단락지을 수 있다) 경우를 생각하자.
이 때, SVM는 주어진 학습용 샘플을, 가장 대담하게 단락짓는 경계선을 학습한다. 학습의 결과 얻을 수 있던 초평면은, 경계에 가장 가까운 샘플과의 거리(마진)가 최대가 되는 퍼셉트론(마진 식별기)으로 정의된다. 즉, 그러한 퍼셉트론의 중량감 벡터 (을)를 이용하고, 초평면은 그리고 나타내진다.


학습 과정은 라그란쥬의 미정 승수법과 KKT 조건을 이용하는 것으로, 최적화 문제의 일종인 철2차 계획 문제로 정식화된다. 다만, 학습 샘플수가 증가하면 급속히 계산량이 증대하기 위해(때문에), 분할 통치법의 생각을 이용한 수법등도 제안되고 있다.
개념적 특징
다음과 같은 학습 데이터 집합 하지만 주어졌을 경우를 생각한다.


(은)는 1혹은—1의 값을 가지는 변수로 하지만 속한 클래스를 의미한다. 하 차원의 특징 벡터이다.



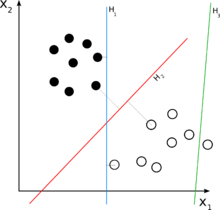
뉴럴 네트워크를 포함한 많은 학습 알고리즘은, 이러한 학습 데이터가 주어졌을 때 인 몇개의 점과 인 몇개의 점을 분리하는 초평면을 찾는 것이 공통의 목표이지만, SVM가 다른 알고리즘과 차별화되는 특징은 단지 몇개의 점을 분리하는 초평면을 찾는 것으로 끝나는 것이 아니라, 몇개의 점을 분리할 수 있는 무수한 후보 평면안에서 마진이 최대가 되는 초평면(maximum-margin hyperplane)을 찾는 점에 있다.여기서 마진이란, 초평면으로부터 각 몇개의점에 이르는 거리의 최소치를 말해, 이 마진을 최대로 하면서 몇개의 점을 두 개의 클래스에서 분류하려고 하면, 결국 클래스 1에 속하는 몇개의 점과의 거리안의 최소치와 클래스-1에 속하는 몇개의 점과의 거리안의 최소치가 동일해지도록(듯이) 초평면이 위치하지 않으면 안되어, 이러한 초평면을 마진 최대의 초평면이라고 한다.결론으로서 SVM는 두 개의 클래스에 속하고 있는 몇개의 점을 분류하는 무수한 초평면안에서, 최대한으로 두 개의 클래스의 몇개의 점과 거리를 유지하는 것을 찾는 알고리즘이라고 할 수 있다.


선형 분리 불가능한 문제에의 적용
1963년에 옷의 안감 미르・바프니크, Alexey Ya. Chervonenkis가 발표한 초기의 서포트 벡터 머신은, 선형 분류기 밖에 적용할 수 없었다. 그러나, 재생핵히르베르트 공간의 이론을 도입한 커넬 함수를 이용해 패턴을 유한 혹은 무한 차원의 특징 공간에 사상해, 특징 공간상에서 선형 분리를 실시하는 수법이 1992년에 Bernhard E. Boser, Isabelle M. Guyon, Vladimir N. Vapnik등에 의해서 제안되었다. 이것에 의해, 비선형 분류 문제에도 뛰어난 성능을 발휘하는 것을 알 수 있어, 근년 특별히 주목을 끌고 있다.
덧붙여 커넬 함수를 도입한 일련의 수법으로는, 어떠한 사상을 할까 알지 못하고 계산할 수 있는 것부터, 커넬 트릭(Kernel Trick)으로 불리고 있다.
주로 아래와 같은 커넬 함수가 잘 사용되고 있어 LIBSVM에서도 실장되고 있다.
구조화 SVM
2005년에 Ioannis Tsochantaridis등이 구조화 SVM(영: structured SVM)를 발표한[2].임의의 데이터 구조를 취급할 수 있도록(듯이) 확장한 것이다.
통상의 2치 분류 SVM는 이하의 값으로 분류한다.

이것은, 이와 같이도 쓸 수 있다.

그 위에, 이것을 2치로부터 일반의 값에 확장한다. (은)는 입출력으로부터 특징량을 만들어 내는 실수 벡터를 돌려주는 함수.문제 마다 정의한다.


그리고, 아래와 같은 손실 함수를 최소화하도록(듯이), 최적화 문제를 푼다.여기에서는 L2마사노리화를 붙이고 있다. (은)는 마사노리화의 힘을 나타내는 정수. (은)는 출력의 유사도를 나타내는 실수를 돌려주는 함수.문제 마다 정의한다. (이어)여, 다른 값끼리라면 0보다 커지도록(듯이) 설계한다.




상기의 최적화 문제를 풀려면 궁리가 필요하고, 그 후도 제안이 계속 되고 있지만, 2005년에 제안된 방법은 아래와 같이 천상의 세계가 되는 함수 (을)를 만든다.


그 위에, 아래와 같은 최적화 문제를 푼다.

의 만드는 방법으로서 2방법이 제안되었다.
- 마진리스케이링
- 스락크리스케이링


관련 항목
- 커넬법
- 순서대로 최소 문제 최적화법(SMO)
- 인공지능
- 패턴 인식
- 방사 기저 함수
- 선형 분류기
- 실장
- LIBSVM(일반), LIBLINEAR(선형)
- scikit-learn(LIBSVM, LIBLINEAR의 Python 래퍼를 포함한다)
참조
- ^ V. Vapnik and A. Lerner. Pattern recognition using generalized portrait method. Automation and Remote Control, 24, 1963.
- ^ Ioannis Tsochantaridis; Thorsten Joachims; Thomas Hofmann; Yasemin Altun (2005). "Large Margin Methods for Structured and Interdependent Output Variables". The Journal of Machine Learning Research 6 (9): 1453-1484.
This article is taken from the Japanese Wikipedia 서포트 벡터 머신
This article is distributed by cc-by-sa or GFDL license in accordance with the provisions of Wikipedia.
In addition, Tranpedia is simply not responsible for any show is only by translating the writings of foreign licenses that are compatible with CC-BY-SA license information.
0 개의 댓글:
댓글 쓰기